When using a between-subjects research design, the database is structured in a fashion that allows for comparison of the independent groups on outcomes.
The first column of any between-subjects database contains a unique numerical de-identifier for each study participant. These ID numbers allow researchers to uphold confidentiality and anonymity of study participants. They also can assist in data validation and manipulation.
A "grouping" variable or categorical predictor variable denoting independent levels or groups should be entered into the second column of the between-subjects database. This "grouping" variable serves as the foundation for conducting between-subjects statistics using software programs.
As researchers create their between-subjects database, they should create a data dictionary so that all research team members will know what data is being collected and what numerical values have been given to the categorical variables.
The first column of any between-subjects database contains a unique numerical de-identifier for each study participant. These ID numbers allow researchers to uphold confidentiality and anonymity of study participants. They also can assist in data validation and manipulation.
A "grouping" variable or categorical predictor variable denoting independent levels or groups should be entered into the second column of the between-subjects database. This "grouping" variable serves as the foundation for conducting between-subjects statistics using software programs.
As researchers create their between-subjects database, they should create a data dictionary so that all research team members will know what data is being collected and what numerical values have been given to the categorical variables.
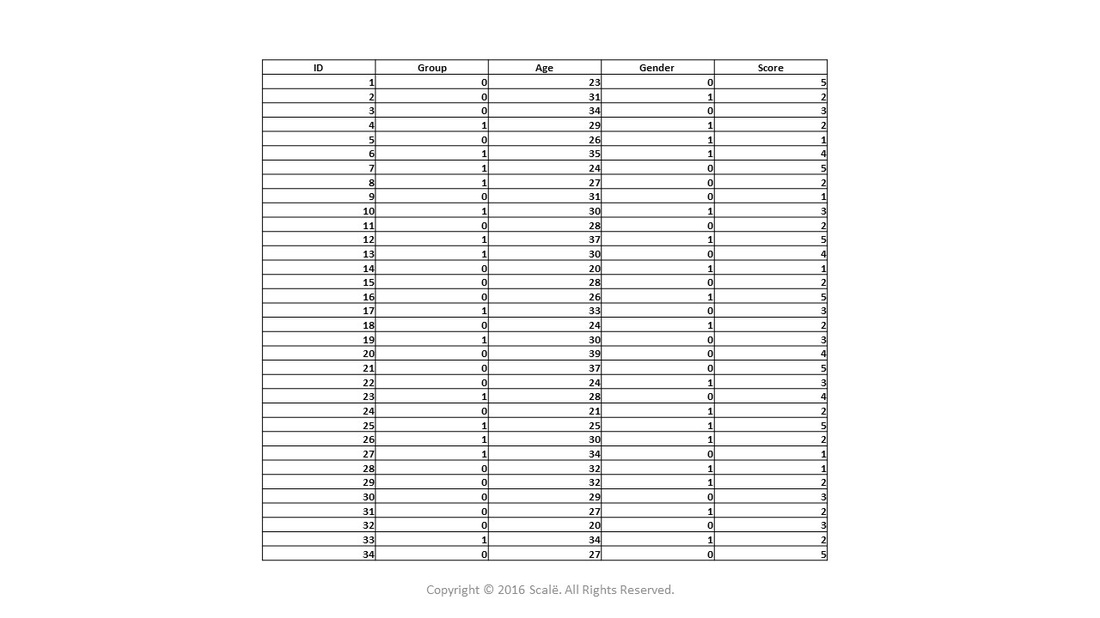
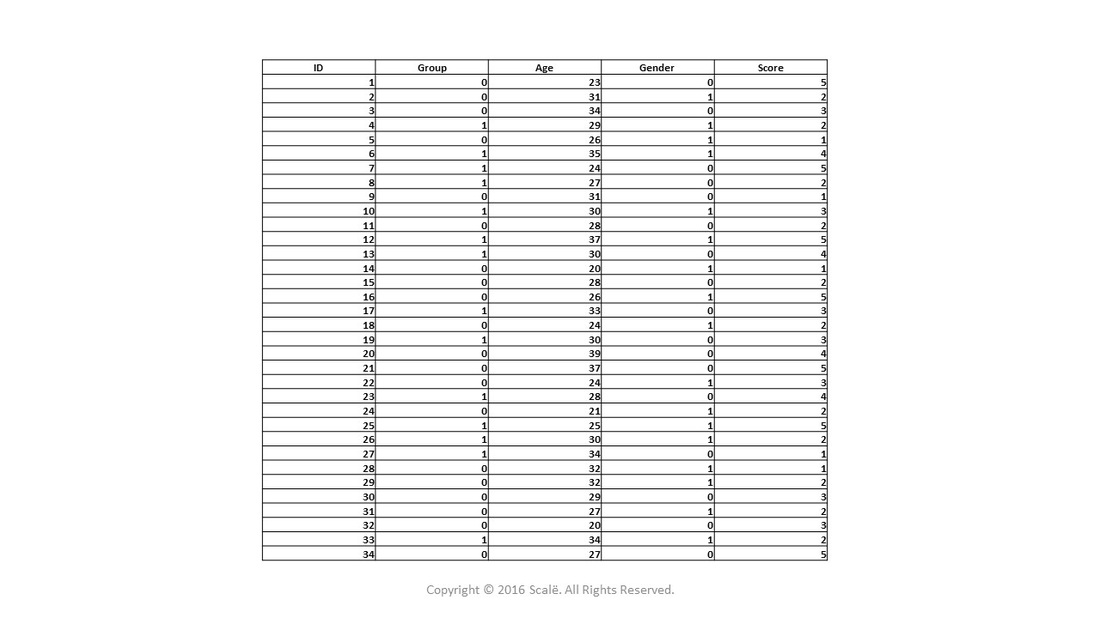
Between-subjects database
Click on the Download Database and Download Data Dictionary buttons for a configured database and data dictionary for between-subjects statistics.