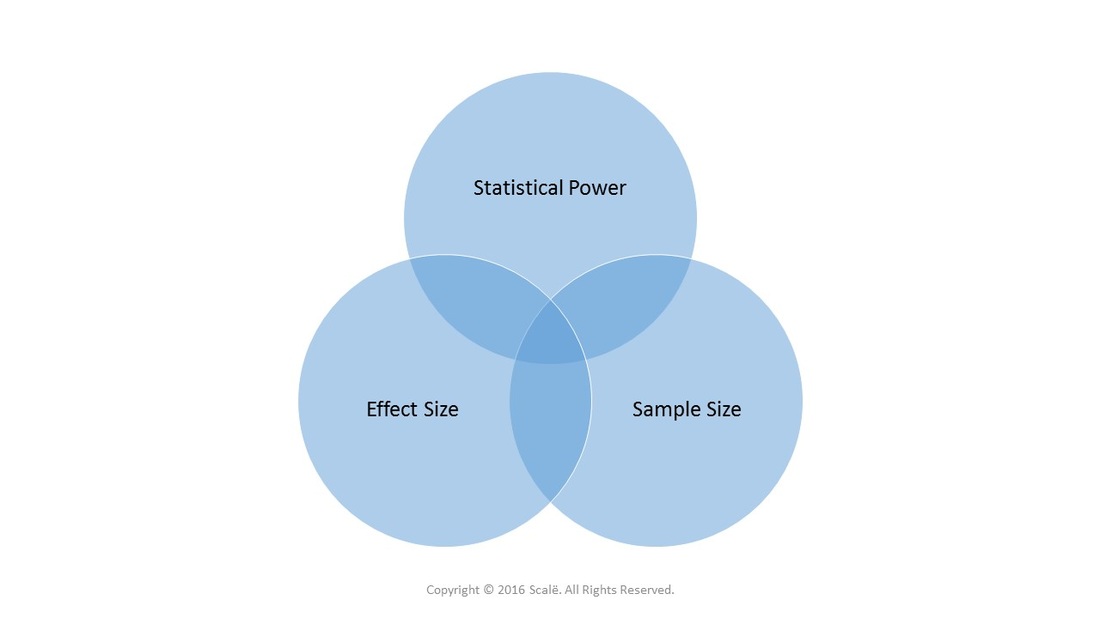
Statistical power and effect size
Within the current empirical or clinical context, are you measuring for a relatively small or large effect size?
Planning and hypothesizing an effect size is oftentimes the hardest part of designing a research study! The choice of effect size has a pervasive impact on your ability to design and conduct a study. If possible, the means, standard deviations, proportions, odds ratios, and risk ratios published in the empirical literature should be used for an effect size. This is called using an evidence-based measure of effect size. Researchers add more internal and external validity to a study when using evidence-based measures of effect size to plan for statistical power and sample size. These values can be found in the text of articles as well as in the tables where groups, observations, associations, or effects are presented.
Some researchers just have NO IDEA what type of effect size they want to measure for in their studies. In these cases, a pilot study of between 150-300 observations of the outcome of interest may be warranted. Pilot studies can yield effect sizes that can be used in both post hoc power analyses and a priori power analyses for future studies.
When the outcome of interest is measured at a continuous level, the effect size is the absolute difference in means, standard deviations, beta weights, and/or standard errors between independent groups (between-subjects design), across multiple observations of an outcome (within-subjects design), or association (multivariate design).
When the outcome of interest is categorical or nominal, the effect size is the absolute difference in proportions, odds, or risk between independent groups (between-subjects designs), across multiple observations of an outcome (within-subjects designs), or adjusted beta weights and distributions (multivariate designs). It is important to understand up front that when researchers choose categorical or nominal outcomes, they automatically will have to collect larger sample sizes to detect significant effects.
The magnitude of an effect is the actual size of the effect. If you are using categorical outcomes, it is the percentage difference between independent groups (between-subjects designs) or observations across time (within-subjects designs). If you expect one group to have a 50% proportion for an outcome and another group to have a 25% prevalence of the outcome, then the effect size is 25%. When using continuous outcomes, the magnitude is the absolute difference in means between independent groups or within-subjects. If you hypothesize that a pre-test score will be 75 and that the post-test score after an educational intervention will be 95, then the effect size is 20 points.
Defining and operationalizing an effect size as being either small or large is done within the current relative clinical or empirical context. Small effect sizes, especially in the case of using categorical outcomes, will drastically increase the needed sample size. If large effect sizes are hypothesized between independent groups or within-subjects, regardless of categorical or continuous measurement, the needed sample size will always decrease and statistical power will increase.
Some researchers just have NO IDEA what type of effect size they want to measure for in their studies. In these cases, a pilot study of between 150-300 observations of the outcome of interest may be warranted. Pilot studies can yield effect sizes that can be used in both post hoc power analyses and a priori power analyses for future studies.
When the outcome of interest is measured at a continuous level, the effect size is the absolute difference in means, standard deviations, beta weights, and/or standard errors between independent groups (between-subjects design), across multiple observations of an outcome (within-subjects design), or association (multivariate design).
When the outcome of interest is categorical or nominal, the effect size is the absolute difference in proportions, odds, or risk between independent groups (between-subjects designs), across multiple observations of an outcome (within-subjects designs), or adjusted beta weights and distributions (multivariate designs). It is important to understand up front that when researchers choose categorical or nominal outcomes, they automatically will have to collect larger sample sizes to detect significant effects.
The magnitude of an effect is the actual size of the effect. If you are using categorical outcomes, it is the percentage difference between independent groups (between-subjects designs) or observations across time (within-subjects designs). If you expect one group to have a 50% proportion for an outcome and another group to have a 25% prevalence of the outcome, then the effect size is 25%. When using continuous outcomes, the magnitude is the absolute difference in means between independent groups or within-subjects. If you hypothesize that a pre-test score will be 75 and that the post-test score after an educational intervention will be 95, then the effect size is 20 points.
Defining and operationalizing an effect size as being either small or large is done within the current relative clinical or empirical context. Small effect sizes, especially in the case of using categorical outcomes, will drastically increase the needed sample size. If large effect sizes are hypothesized between independent groups or within-subjects, regardless of categorical or continuous measurement, the needed sample size will always decrease and statistical power will increase.
How large or small will the effect size be in the research study?
A relatively small difference between independent means and variances, independent proportions, or a small treatment effect within the current context.
A relatively large difference between independent means and variances, independent proportions, or a larger treatment effect within the current context.

Statistician For Hire
DO YOU NEED TO HIRE A STATISTICIAN?
Eric Heidel, Ph.D. will provide statistical consulting for your research study at $100/hour. Secure checkout is available with PayPal, Stripe, Venmo, and Zelle.
- Statistical Analysis
- Sample Size Calculations
- Diagnostic Testing and Epidemiological Calculations
- Psychometrics