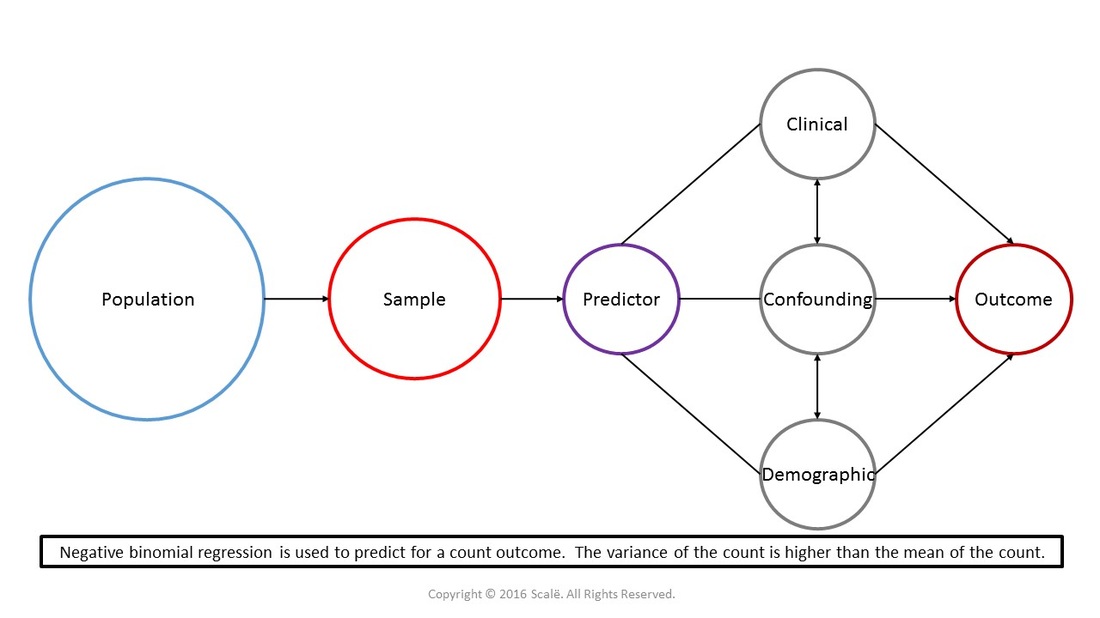
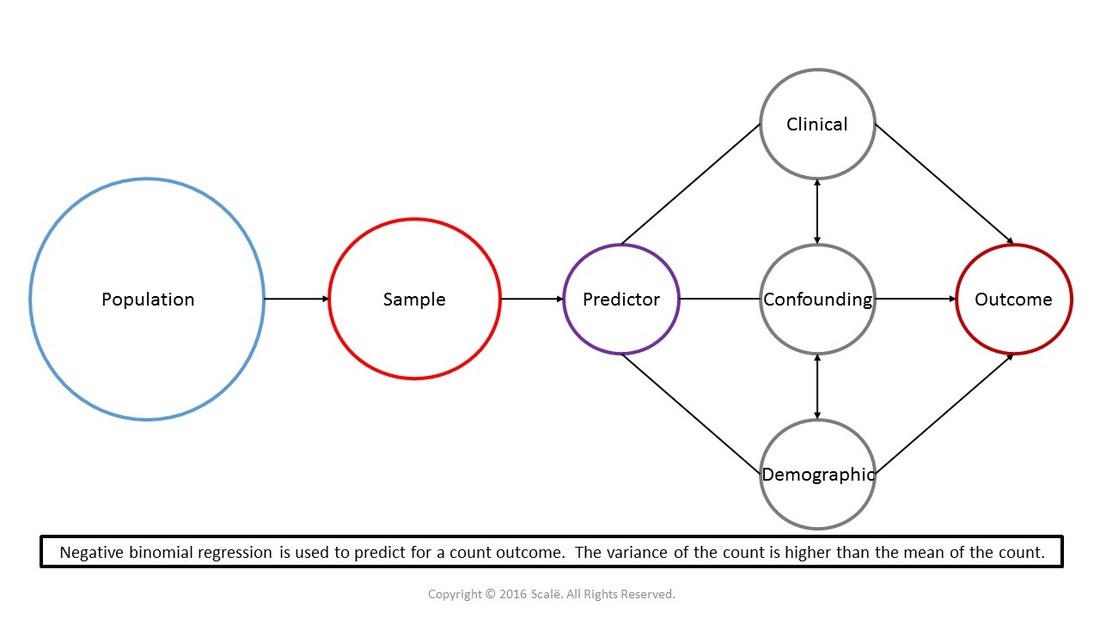
Negative binomial regression is used to test for associations between predictor and confounding variables on a count outcome variable when the variance of the count is higher than the mean of the count. Negative binomial regression is interpreted in a similar fashion to logistic regression with the use of odds ratios with 95% confidence intervals. Just like with other forms of regression, the assumptions of linearity, homoscedasticity, and normality have to be met for negative binomial regression.
1. The data is entered in a multivariate fashion.
2. Click Analyze.
3. Drag the cursor over the Generalized Linear Models drop-down.
4. Click Generalized Linear Model.
5. In the Type of Model tab, under the Counts header, click on the Negative binomial with log link marker to select it.
6. Click on the Response tab.
7. Click on the count outcome variable in the Variables: box to highlight it.
8. Click on the arrow to move the variable into the Dependent Variable: box.
9. Click on the Predictors tab.
10. Click on a categorical or ordinal predictor variable in the Variables: box to highlight it.
11. Click on the arrow to move the variable into the Factors: box.
12. Repeat Steps 10 and 11 until all of the categorical predictor variables are in the Variables: box.
13. Click on a continuous predictor variable in the Variables: box to highlight it.
14. Click on the arrow to move the variable into the Covariates: box.
15. Repeat Steps 13 and 14 until all of the continuous predictor variables are in the Covariates: box.
16. Click on the Model tab.
17. Look in the Factors and Covariates: box. Click on the first predictor variable to highlight it.
18. Click on the arrow to move the variable into the Model: box.
19. Repeat Steps 17 and 18 until all of the predictor variables are in the Model: box.
20. Click on the EM Means tab.
21. In the Factors and Interactions: table, click on the first predictor variable to highlight it.
22. Click on the arrow to move the variable into the Display Means for: box.
23. Repeat Steps 21 and 22 until all of the predictor variables are in the Display Means for: box.
24. Click on the Save tab.
25. Click on the Predicted value of mean of response, Standardized Pearson residual, and Standardized deviance residual boxes to select them.
26. Click OK.
2. Click Analyze.
3. Drag the cursor over the Generalized Linear Models drop-down.
4. Click Generalized Linear Model.
5. In the Type of Model tab, under the Counts header, click on the Negative binomial with log link marker to select it.
6. Click on the Response tab.
7. Click on the count outcome variable in the Variables: box to highlight it.
8. Click on the arrow to move the variable into the Dependent Variable: box.
9. Click on the Predictors tab.
10. Click on a categorical or ordinal predictor variable in the Variables: box to highlight it.
11. Click on the arrow to move the variable into the Factors: box.
12. Repeat Steps 10 and 11 until all of the categorical predictor variables are in the Variables: box.
13. Click on a continuous predictor variable in the Variables: box to highlight it.
14. Click on the arrow to move the variable into the Covariates: box.
15. Repeat Steps 13 and 14 until all of the continuous predictor variables are in the Covariates: box.
16. Click on the Model tab.
17. Look in the Factors and Covariates: box. Click on the first predictor variable to highlight it.
18. Click on the arrow to move the variable into the Model: box.
19. Repeat Steps 17 and 18 until all of the predictor variables are in the Model: box.
20. Click on the EM Means tab.
21. In the Factors and Interactions: table, click on the first predictor variable to highlight it.
22. Click on the arrow to move the variable into the Display Means for: box.
23. Repeat Steps 21 and 22 until all of the predictor variables are in the Display Means for: box.
24. Click on the Save tab.
25. Click on the Predicted value of mean of response, Standardized Pearson residual, and Standardized deviance residual boxes to select them.
26. Click OK.
With more complex statistics such as a negative binomial regression, a little bit more complexity is necessitated to run the analysis. Researchers are going to have to use syntax to get the adjusted odds ratios and 95% confidence intervals for the model. SPSS does not have a point-and-click button for these important values. However, do not fret! It is very simple to do. Here are the steps:
1. Go to the output file.
2. Scroll up to the very top of the output where the syntax code for the analysis is located.
3. Click in the area of the syntax code and it will become highlighted.
4. Use the cursor to highlight all of the syntax code and COPY it by right-clicking your mouse and selecting Copy or press Ctrl + c.
5. Look in the upper left hand part of the computer screen for the File drop down menu.
6. Click on the File drop-down menu.
7. Drag the cursor over the New drop-down menu.
8. Click Syntax.
9. Paste the syntax code into the syntax editor.
10. The last line of the syntax code should end with SOLUTION.
11. Type the last line of code like this: SOLUTION (EXPONENTIATED).
12. Use the cursor to highlight all of the new syntax code.
13. Click the Green triangle to run the code. (Looks like a green "play" button)
1. Go to the output file.
2. Scroll up to the very top of the output where the syntax code for the analysis is located.
3. Click in the area of the syntax code and it will become highlighted.
4. Use the cursor to highlight all of the syntax code and COPY it by right-clicking your mouse and selecting Copy or press Ctrl + c.
5. Look in the upper left hand part of the computer screen for the File drop down menu.
6. Click on the File drop-down menu.
7. Drag the cursor over the New drop-down menu.
8. Click Syntax.
9. Paste the syntax code into the syntax editor.
10. The last line of the syntax code should end with SOLUTION.
11. Type the last line of code like this: SOLUTION (EXPONENTIATED).
12. Use the cursor to highlight all of the new syntax code.
13. Click the Green triangle to run the code. (Looks like a green "play" button)
1. Look in the Goodness of Fit table, at the Value/df column for the Pearson Chi-Square row.
If the value is LESS THAN .05, then the model does not fit the data well and other analyses should be considered.
If the value is MORE THAN .05, then the model does the fit the data well and researchers can continue with interpreting the results.
2. Look in the Omnibus Test table, under the Sig. column. This is the p-value that is interpreted.
If the p-value is LESS THAN .05, then researchers have statistically significant model and should continue interpreting the results.
If the p-value is MORE THAN .05, then researchers do not have a significant model. Report the p-values as needed.
3. Look in the Tests of Model Effects table, under the Sig., Exp(B), Lower, and Upper columns.
For categorical or ordinal predictors:
The last category of the categorical or ordinal variable is going to serve as the reference group for interpretation purposes.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is above 1.0, the risk of the outcome occurring increases that many more times versus the reference category.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is below 1.0, then the risk of the outcome occurring decreases that many times versus the reference category.
If the p-value is MORE THAN .05, then the 95% CI for the adjusted odds ratio crosses over 1.0 and the association is non-significant.
For continuous predictors:
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is above 1.0, for every one-unit increase in the continuous variable, the risk of the outcome occurring increases that many more times versus the reference category.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is below 1.0, for every one-unit increase in the continuous variable, the risk of the outcome occurring decreases that many times versus the reference category.
If the value is LESS THAN .05, then the model does not fit the data well and other analyses should be considered.
If the value is MORE THAN .05, then the model does the fit the data well and researchers can continue with interpreting the results.
2. Look in the Omnibus Test table, under the Sig. column. This is the p-value that is interpreted.
If the p-value is LESS THAN .05, then researchers have statistically significant model and should continue interpreting the results.
If the p-value is MORE THAN .05, then researchers do not have a significant model. Report the p-values as needed.
3. Look in the Tests of Model Effects table, under the Sig., Exp(B), Lower, and Upper columns.
For categorical or ordinal predictors:
The last category of the categorical or ordinal variable is going to serve as the reference group for interpretation purposes.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is above 1.0, the risk of the outcome occurring increases that many more times versus the reference category.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is below 1.0, then the risk of the outcome occurring decreases that many times versus the reference category.
If the p-value is MORE THAN .05, then the 95% CI for the adjusted odds ratio crosses over 1.0 and the association is non-significant.
For continuous predictors:
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is above 1.0, for every one-unit increase in the continuous variable, the risk of the outcome occurring increases that many more times versus the reference category.
If the p-value is LESS THAN .05 and the adjusted odds ratio with its 95% CI is below 1.0, for every one-unit increase in the continuous variable, the risk of the outcome occurring decreases that many times versus the reference category.
At this point, researchers need to construct and interpret several plots of the raw and standardized residuals to fully assess model fit. Residuals can be thought of as the error associated with predicting or estimating outcomes using predictor variables. Residual analysis is extremely important for meeting the linearity, normality, and homogeneity of variance assumptions of negative binomial regression.
Here is how to conduct the analysis in SPSS:
1. Go back to the Data View. There are three new variables that have been created.
The first is the predicted value of the mean of response of that observation and is given the variable name MeanPredicted.
The second variable contains the standardized Pearson residual and is given the variable name of StdPearsonResidual.
The third variable has standardized Deviance residuals and will be given the variable name of as StdDevianceResidual.
2. Click Graphs.
3. Drag the cursor over the Legacy Dialogs drop-down menu.
4. Click Scatter/Dot.
5. Click Simple Scatter to select it.
6. Click Define.
7. Click on the StdDevianceResidual variable to highlight it.
8. Click on the arrow to move the variable into the Y Axis: box.
9. Click on the MeanPredicted variable to highlight it.
10. Click on the arrow to move the variable into the X Axis: box.
11. Click OK.
1. Go back to the Data View. There are three new variables that have been created.
The first is the predicted value of the mean of response of that observation and is given the variable name MeanPredicted.
The second variable contains the standardized Pearson residual and is given the variable name of StdPearsonResidual.
The third variable has standardized Deviance residuals and will be given the variable name of as StdDevianceResidual.
2. Click Graphs.
3. Drag the cursor over the Legacy Dialogs drop-down menu.
4. Click Scatter/Dot.
5. Click Simple Scatter to select it.
6. Click Define.
7. Click on the StdDevianceResidual variable to highlight it.
8. Click on the arrow to move the variable into the Y Axis: box.
9. Click on the MeanPredicted variable to highlight it.
10. Click on the arrow to move the variable into the X Axis: box.
11. Click OK.
1. If there are not significant deviations away from 0 and 95% of the residuals are under absolute value of 2.0, then the model is thought to fit the data.
Normality and equal variance assumptions apply to negative binomial regression analyses. Here is how to assess outliers in the dataset:
1. Click Analyze.
2. Drag the cursor over the Descriptive Statistics drop-down menu.
3. Click Frequencies.
4. Click on the StdPearsonResidual variable to highlight it.
5. Click on the arrow to move the variable into the Variable(s): box.
6. Click OK.
2. Drag the cursor over the Descriptive Statistics drop-down menu.
3. Click Frequencies.
4. Click on the StdPearsonResidual variable to highlight it.
5. Click on the arrow to move the variable into the Variable(s): box.
6. Click OK.
1. Look in the Standardized Pearson Residual table, under the first column. (It has the word "Valid" in it).
2. Scroll through the entirety of the table.
3. If there are values that are above an absolute value of 2.0, then are outliers.
2. Scroll through the entirety of the table.
3. If there are values that are above an absolute value of 2.0, then are outliers.
Click on the Download Database and Download Data Dictionary buttons for a configured database and data dictionary for negative binomial regression. Click on the Validation of Statistical Findings button to learn more about bootstrap, split-group, and jack-knife validation methods.