Logistic regression is the multivariate extension of a bivariate chi-square analysis. Logistic regression allows for researchers to control for various demographic, prognostic, clinical, and potentially confounding factors that affect the relationship between a primary predictor variable and a dichotomous categorical outcome variable. Logistic regression generates adjusted odds ratios with 95% confidence intervals. Logistic regression is published often in the medical literature and provides a measure of strength of relationship to a dichotomous categorical outcome when controlling for other variables.
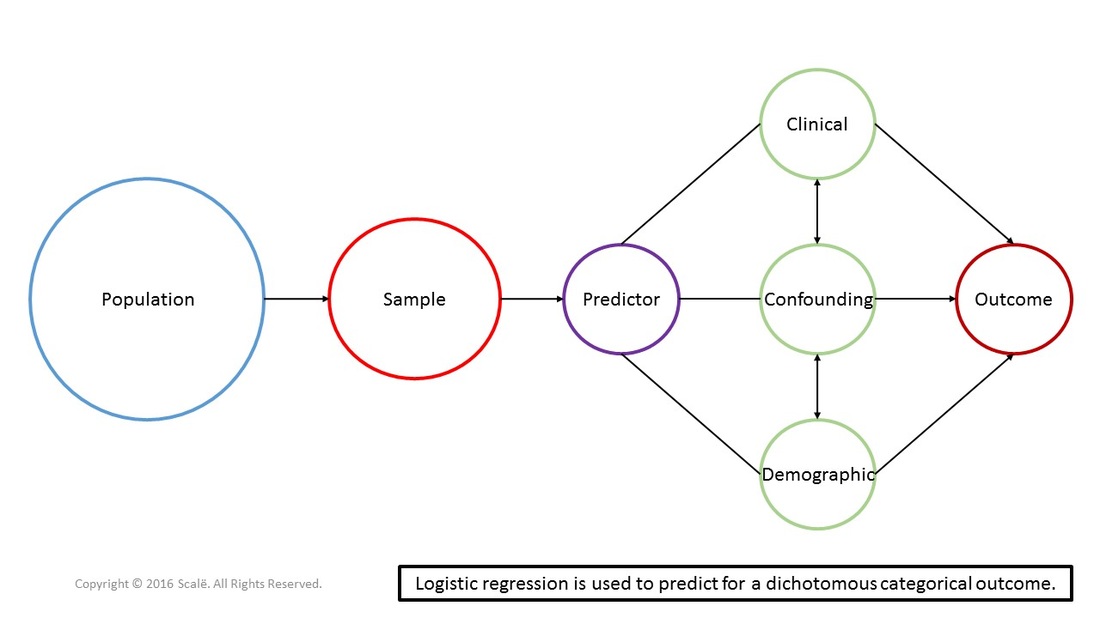
The figure below depicts the use of logistic regression. Predictor, clinical, confounding, and demographic variables are being used to predict for a dichotomous categorical outcome. Logistic regression is a multivariate analysis that can yield adjusted odds ratios with 95% confidence intervals.
1. The data is entered in a between-subjects fashion. The dichotomous categorical outcome is codified with "0" not having the outcome and "1" having the outcome. Categorical predictor variables with two levels are codified as 0 = NOT having the characteristic and 1 = HAVING the characteristic. Polychotomous categorical variables have a reference category that is codified as "0."
2. Click Analyze.
3. Drag the cursor over the Regression drop-down menu.
4. Click Binary Logistic.
5. Click on the dichotomous categorical outcome variable to highlight it.
6. Click on the arrow to move the variable into the Dependent: box.
7. Click on the primary predictor variable to highlight it.
8. Click on the arrow to move the variable into the Covariates: box.
9. Repeat Steps 7 and 8 until all of the predictor, clinical, confounding, and demographic variables are moved into the Covariates: box.
10. Click on the Categorical button if researchers moved any categorical variables into the Covariates: box.
11. Click on the categorical variable in the Covariates: box to highlight it.
12. Click on the arrow to move the variable into the Categorical Covariates: box.
13. Click on the Reference Category: First marker.
14. Click Change.
15. Repeat Steps 11, 12, 13, and 14 until all of the categorical variables are in the Categorical Covariates: box.
16. Click Continue.
17. Click on the Save button.
18. In the Residuals table, click on the Unstandardized and Standardized boxes to select them.
19. In the Predicted Values table, click on the Probabilities box to select it.
20. Click Continue.
21. Click on the Options button.
22. In the Statistics and Plots table, click on the Hosmer-Lemeshow goodness-of-fit, Casewise listing of residuals, and CI for exp(B): boxes to select them.
23. Click Continue.
24. Click OK.
2. Click Analyze.
3. Drag the cursor over the Regression drop-down menu.
4. Click Binary Logistic.
5. Click on the dichotomous categorical outcome variable to highlight it.
6. Click on the arrow to move the variable into the Dependent: box.
7. Click on the primary predictor variable to highlight it.
8. Click on the arrow to move the variable into the Covariates: box.
9. Repeat Steps 7 and 8 until all of the predictor, clinical, confounding, and demographic variables are moved into the Covariates: box.
10. Click on the Categorical button if researchers moved any categorical variables into the Covariates: box.
11. Click on the categorical variable in the Covariates: box to highlight it.
12. Click on the arrow to move the variable into the Categorical Covariates: box.
13. Click on the Reference Category: First marker.
14. Click Change.
15. Repeat Steps 11, 12, 13, and 14 until all of the categorical variables are in the Categorical Covariates: box.
16. Click Continue.
17. Click on the Save button.
18. In the Residuals table, click on the Unstandardized and Standardized boxes to select them.
19. In the Predicted Values table, click on the Probabilities box to select it.
20. Click Continue.
21. Click on the Options button.
22. In the Statistics and Plots table, click on the Hosmer-Lemeshow goodness-of-fit, Casewise listing of residuals, and CI for exp(B): boxes to select them.
23. Click Continue.
24. Click OK.
1. Scroll down to the Block 1: Method = Enter section of the output.
2. Look in the Omnibus Tests of Model Coefficients table, under the Sig. column, in the Model row. This is the p-value that is interpreted.
If the p-value is LESS THAN .05, then researchers have a significant model that should be further interpreted.
If the p-value is MORE THAN .05, then researchers do not have a significant model and the results should be reported.
3. Look in the Hosmer and Lemeshow Test table, under the Sig. column. This is the p-value you will interpret.
If the p-value is LESS THAN .05, then the model does not fit the data.
If the p-value is MORE THAN .05, then the model does fit the data and should be further interpreted.
4. Look in the Classification Table, under the Percentage Correct in the Overall Percentage row. This is the total accuracy of the model. Researchers want it to ultimately be at least 80%.
5. Look in the Variables in the Equation table, under the Sig., Exp(B), and Lower and Upper columns. The Sig. column is the p-value associated with the adjusted odds ratios and 95% CIs for each predictor, clinical, demographic, or confounding variable. The value in the Exp(B) is the adjusted odds ratio. The Lower and Upper values are the limits of the 95% CI associated with the adjusted odds ratio.
6. Researchers will interpret the adjusted odds ratio in the Exp(B) column and the confidence interval in the Lower and Upper columns for each variable.
If the confidence interval associated with the adjusted ratio crosses over 1.0, then there is a non-significant association. The p-value associated with these variables will also be HIGHER than .05.
If the adjusted odds ratio is ABOVE 1.0 and the confidence interval is entirely above 1.0, then exposure to the predictor increases the odds of the outcome.
If the adjusted odds ratio is BELOW 1.0 and the confidence interval is entirely below 1.0, then exposure to the predictor decreases the odds of the outcome.
If the variable is measured at the ordinal or continuous level, then the adjusted odds ratio is interpreted as meaning for every one unit increase in the ordinal or continuous variable, the risk of the outcome increases at the rate specified in the odds ratio.
2. Look in the Omnibus Tests of Model Coefficients table, under the Sig. column, in the Model row. This is the p-value that is interpreted.
If the p-value is LESS THAN .05, then researchers have a significant model that should be further interpreted.
If the p-value is MORE THAN .05, then researchers do not have a significant model and the results should be reported.
3. Look in the Hosmer and Lemeshow Test table, under the Sig. column. This is the p-value you will interpret.
If the p-value is LESS THAN .05, then the model does not fit the data.
If the p-value is MORE THAN .05, then the model does fit the data and should be further interpreted.
4. Look in the Classification Table, under the Percentage Correct in the Overall Percentage row. This is the total accuracy of the model. Researchers want it to ultimately be at least 80%.
5. Look in the Variables in the Equation table, under the Sig., Exp(B), and Lower and Upper columns. The Sig. column is the p-value associated with the adjusted odds ratios and 95% CIs for each predictor, clinical, demographic, or confounding variable. The value in the Exp(B) is the adjusted odds ratio. The Lower and Upper values are the limits of the 95% CI associated with the adjusted odds ratio.
6. Researchers will interpret the adjusted odds ratio in the Exp(B) column and the confidence interval in the Lower and Upper columns for each variable.
If the confidence interval associated with the adjusted ratio crosses over 1.0, then there is a non-significant association. The p-value associated with these variables will also be HIGHER than .05.
If the adjusted odds ratio is ABOVE 1.0 and the confidence interval is entirely above 1.0, then exposure to the predictor increases the odds of the outcome.
If the adjusted odds ratio is BELOW 1.0 and the confidence interval is entirely below 1.0, then exposure to the predictor decreases the odds of the outcome.
If the variable is measured at the ordinal or continuous level, then the adjusted odds ratio is interpreted as meaning for every one unit increase in the ordinal or continuous variable, the risk of the outcome increases at the rate specified in the odds ratio.
At this point, researchers need to construct and interpret several plots of the raw and standardized residuals to fully assess the fit of your model. Residuals can be thought of as the error associated with predicting or estimating outcomes using predictor variables. Residual analysis is extremely important for meeting the linearity, normality, and homogeneity of variance assumptions of logistic regression.
1. Go back to the Data View. There are three new variables that have been created.
The first is the predicted probability of that observation and is given the variable name of PRE_1.
The second variable contains the raw residuals (the difference between the observed and predicted probabilities of the model) and is given the variable name of RES_1.
The third variable has standardized residuals based on the raw residuals in the second variable and will be given the variable name of as ZRE_1.
2. Click Graphs.
3. Drag the cursor over the Legacy Dialogs drop-down menu.
4. Click Scatter/Dot.
5. Click Simple Scatter to select it.
6. Click Define.
7. Click on the RES_1 or raw residual variable to highlight it.
8. Click on the arrow to move the variable into the Y Axis: box.
9. Click on the PRE_1 or predicted probability variable to highlight it.
10. Click on the arrow to move the variable into the X Axis: box.
11. Click OK.
The first is the predicted probability of that observation and is given the variable name of PRE_1.
The second variable contains the raw residuals (the difference between the observed and predicted probabilities of the model) and is given the variable name of RES_1.
The third variable has standardized residuals based on the raw residuals in the second variable and will be given the variable name of as ZRE_1.
2. Click Graphs.
3. Drag the cursor over the Legacy Dialogs drop-down menu.
4. Click Scatter/Dot.
5. Click Simple Scatter to select it.
6. Click Define.
7. Click on the RES_1 or raw residual variable to highlight it.
8. Click on the arrow to move the variable into the Y Axis: box.
9. Click on the PRE_1 or predicted probability variable to highlight it.
10. Click on the arrow to move the variable into the X Axis: box.
11. Click OK.
1. If the points along the scatterplot are symmetric both above and below a straight line, with observations being equally spaced out along the line, then the assumption of linearity can be assumed. Interpretation of these types of scatterplot graphs allows for some subjectivity in regards to symmetry and spread along the line.
If there are significantly larger residuals and wider dispersal of observations along the line, then linearity cannot be assumed.
If there are significantly larger residuals and wider dispersal of observations along the line, then linearity cannot be assumed.
Normality and equal variance assumptions apply to logistic regression analyses. Here is how to assess if there are any outliers in the dataset.
1. Click Analyze.
2. Drag the cursor over the Descriptive Statistics drop-down menu.
3. Click Frequencies.
4. Click on the ZRE_1 or standardized residuals variable to highlight it.
5. Click on the arrow to move the variable into the Variable(s): box.
6. Click OK.
2. Drag the cursor over the Descriptive Statistics drop-down menu.
3. Click Frequencies.
4. Click on the ZRE_1 or standardized residuals variable to highlight it.
5. Click on the arrow to move the variable into the Variable(s): box.
6. Click OK.
1. Look in the Normalized residual table, under the first column. (It has the word "Valid" in it).
2. Scroll through the entirety of the table.
3. If there are values that are above an absolute value of 2.0, then there are outliers in the dataset.
2. Scroll through the entirety of the table.
3. If there are values that are above an absolute value of 2.0, then there are outliers in the dataset.
Click on the Download Database and Download Data Dictionary buttons for a configured database and data dictionary for logistic regression. Click on the Validation of Statistical Findings button to learn more about bootstrap, split-group, and jack-knife validation methods.